
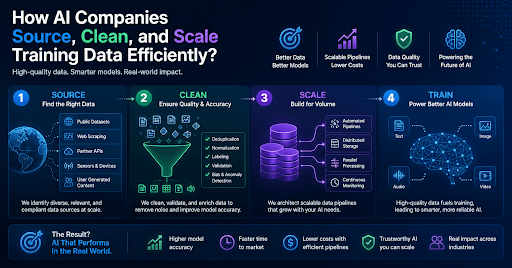
Introduction
Building a capable AI model demands one foundational resource above everything else: high-quality training data. The process of collecting, refining, and expanding that data at scale involves far more engineering rigor than most people outside the field realize. Every architectural decision made during this phase has a direct impact on model accuracy, fairness, and commercial viability.
For engineers, researchers, and enterprise teams evaluating AI systems, understanding AI data sourcing strategies, training data pipelines, and modern data management tooling is no longer optional. It is a core competency. This guide walks through each phase with the precision that practitioners actually need.
How Do AI Companies Source Training Data?
Training data sourcing sits at the foundation of any model development effort. Most leading labs draw from three distinct channels, and the strongest datasets typically combine all of them. For organizations looking to operationalize this at scale, AI training data scraping services provide a structured way to acquire high-quality, domain-specific datasets efficiently.
Web Crawling and Public Datasets
The majority of large language models train on publicly available text gathered through large-scale web crawls. Common Crawl remains one of the most widely used sources, containing petabytes of raw web content referenced by OpenAI, Meta, and Google DeepMind alike. Academic repositories such as Wikipedia, BooksCorpus, and the C4 corpus (Colossal Clean Crawled Corpus) contribute structured, relatively clean text that serves as a reliable foundation for open-source training datasets across many model families.
Licensed and Proprietary Data
Data from the public alone is rarely good enough for production-grade models. Therefore, companies actively license content from publishers, legal databases, and media organizations. OpenAI has formalized agreements with outlets including The Associated Press and Axel Springer to access editorially curated material. This category of licensed AI training data significantly reduces copyright exposure while pushing the average quality of training corpora upward.
Synthetic Data Generation
Synthetic data generation has moved from a niche technique to a mainstream component of AI training data collection. Models generate their own training examples through methods including self-play, model distillation, and structured prompt-response generation. Both Google Gemini and Meta LLaMA 3 incorporate substantial synthetic data volumes.
Gartner projects that by 2026, more than 75% of enterprise AI training datasets will contain synthetically generated content. The primary motivation goes beyond cost savings. Synthetic generation allows teams to cover edge cases and rare linguistic or visual scenarios that organic data collection cannot realistically provide.
What Does the Data Cleaning Process Look Like?
AI data cleaning, also referred to as data preprocessing or data curation, converts raw collected content into structured, model-ready inputs. Poor data hygiene at this stage is one of the most common and least-discussed causes of underperforming models in real-world deployment.
Deduplication comes first. Duplicate documents distort the training signal and inflate the apparent dataset size. MinHash LSH and other locality-sensitive hashing methods detect near-duplicate content at a petabyte scale without requiring pairwise comparisons.
Quality filtering follows deduplication. Using fastText Classifiers, you can give each document a quality evaluation on the basis of language accuracy, fluency, and topic relevance. To get rid of junk information such as redundant text, spam content, and machine-generated noise, Perplexity-based scoring is used to remove items that add nothing productive to the machine learning data pipeline.
Bias auditing looks at representational fairness; both automated classifiers and human readers will identify potential demographic imbalance and show evidence of political or cultural bias in any corpus. This will influence how models behave in sensitive areas.
The process of stripping out PII protects the individual user’s personal privacy and meets regulatory requirements for compliance, under both the GDPR and CCPA. Named Entity Recognition systems and rule-based regular expressions are used together to remove PII before data can enter any training system.
Annotation and labeling add structured supervision signals. Platforms including Scale AI and Appen provide human annotators for classification, named entity recognition, and reinforcement learning from human feedback tasks. Anthropic and Google DeepMind additionally use internal quality scoring rubrics that assign each document a numerical grade based on factual density, source credibility, and writing clarity.
Format normalization closes the preprocessing stage. All inputs are standardized into consistent schemas, tokenized, and validated before entering the model training infrastructure.
How Do AI Companies Scale Training Data at Volume?
Scaling machine learning training data from billions to trillions of tokens requires deliberate infrastructure design, not simply larger storage buckets.
| Scaling Strategy | Function | Adopted By |
| Active learning | Identifies high-uncertainty examples for targeted human review. | Scale AI, Labelbox |
| Data flywheel | Converts user interactions into continuously refreshed labeled examples. | OpenAI, Google |
| Federated collection | Runs on-device training without centralizing raw user data. | Apple, Google |
| Multimodal pipelines | Unifies text, image, audio, and video ingestion into one corpus. | OpenAI GPT-4V, Gemini |
| Curriculum learning | Sequences data from simple to complex to accelerate convergence. | DeepMind, Meta AI |
Teams can manage datasets that are hundreds of terabytes big without causing training delays thanks to distributed storage formats like Apache Parquet and cloud object stores like AWS S3 and Google Cloud Storage. The compute-storage separation concept is now typical in all enterprise ML operations. It is the key to how current AI data infrastructure can be both large and cost-effective at the same time.
What Tools Power AI Data Management?
The production-grade AI data management stack blends open-source tooling with enterprise platforms. The most widely deployed tools include the following:
Apache Spark for distributed transformation, filtering, and large-scale deduplication.
dbt for version-controlled data transformations with full lineage documentation.
Weights and Biases for experiment tracking and dataset versioning across training runs.
Hugging Face Datasets for standardized loading and sharing of NLP and multimodal data.
DVC for Git-style versioning of both datasets and trained model artifacts.
Label Studio and Scale AI for structured human annotation across supervised learning tasks.
Databricks Delta Lake for ACID-compliant, enterprise-scale data lake operations.
Together, these tools support reproducible, auditable AI training data pipelines that can withstand both technical scrutiny and emerging regulatory review requirements.
Why Data Quality Outweighs Data Volume
Recent research has substantially revised earlier assumptions about the relationship between dataset size and model performance. Meta’s LLaMA 3 technical report documented cases where a smaller, rigorously curated corpus outperformed significantly larger but noisier datasets on standard benchmarks. Mistral AI demonstrated similar findings, achieving strong benchmark results against much larger competitors through disciplined high-quality curated training data selection rather than scale-first strategies.
The underlying reason is straightforward. Low-quality or redundant tokens consume compute allocation without improving model generalization. Therefore, top AI research labs now dedicate substantial engineering capacity to data quality improvement programs, often investing more in curation infrastructure than in model architecture research itself.
Legal and Ethical Dimensions of AI Data Sourcing
Multiple jurisdictions are making changes to how AI training datasets comply with regulations. At the same time, lawsuits from Getty Images and The New York Times raise serious concerns regarding whether use of copyrighted material to train models qualifies under the doctrine of fair use or constitutes infringement.
Regulatory frameworks are moving in parallel. Leading organizations are responding by implementing governance systems that track data source origins and licensing terms, maintain opt-out mechanisms for content creators, preserve audit logs of all filtering and transformation decisions, and document consent frameworks for any user-generated content used in fine-tuning.
Thus, as a result of responsible AI Data Sourcing, organizations have moved away from simply checking a box for legal requirements to legitimate differentiation within products. Transparency and well-governed processes through the utilization of a transparent and well-governed pipeline will create significant advantages for organizations across the continuum of regulatory preparedness, partnership trust, and long-term model reliability.
Conclusion
The quality of an AI model is ultimately a reflection of the data it was trained on. Sourcing diverse, legally sound, and domain-relevant content, cleaning it with precision through deduplication, filtering, and bias auditing, and scaling it through intelligent infrastructure are not separate engineering concerns. They form a single, interconnected discipline that determines how well any model performs in production.
As regulatory scrutiny intensifies and model benchmarks grow more demanding, AI training data management will only increase in strategic importance. Organizations that treat data as a first-class engineering asset rather than a preprocessing afterthought will consistently build more reliable, more compliant, and more capable AI systems. The technical foundations covered in this guide represent the current standard of practice across leading labs and enterprise AI teams globally.