
Introduction to Support Vector Machines
Walk into any data science team meeting, and you will hear passionate debates about which machine learning algorithm reigns supreme. Yet, one algorithm consistently earns respect from both seasoned practitioners and academic researchers: support vector machines. This remarkably effective classification technique has earned its place in the machine learning hall of fame through decades of reliable performance across countless real world applications.
What makes support vector machines so special? Unlike many algorithms that simply draw any line to separate data points, SVM takes a more thoughtful approach. It searches for the absolute best boundary, the one that creates the widest possible separation between categories. This pursuit of optimal separation leads to models that make predictions with exceptional confidence and accuracy.
A Different Way of Thinking About Classification
Imagine you are a security guard tasked with separating two groups of people in a crowded hall. Any line you draw will separate them, but the best line keeps everyone at a comfortable distance from each other, reducing the chance of accidental mingling. Support vector machines operate on this same intuitive principle. They do not just separate data; they create boundaries with breathing room.
This philosophy of maximizing separation has deep roots in machine learning history. The evolution of machine learning algorithms shows how SVM represented a significant advancement over earlier methods by prioritizing generalization over mere training accuracy. When you build an SVM model, you are not just teaching it to memorize your training data; you are teaching it to understand the underlying structure that will perform well on future, unseen data.
Where SVM Shines Brightest
Support vector machines excel in scenarios where data is complex yet structured. They handle high dimensional problems with grace, making them a favorite for text analysis where thousands of features are common. They also perform remarkably well with smaller datasets where deep learning models might struggle due to insufficient training examples.
The algorithm’s versatility extends beyond simple binary decisions. Through clever extensions, SVM handles multiclass problems and even regression tasks. Whether you are building a spam filter, diagnosing diseases from medical images, or predicting stock market movements, support vector machines offer a reliable path forward.
The Core Ideas Behind SVM
To truly appreciate support vector machines, you need to understand the simple yet powerful concepts that drive their decision making.
The Quest for the Perfect Line
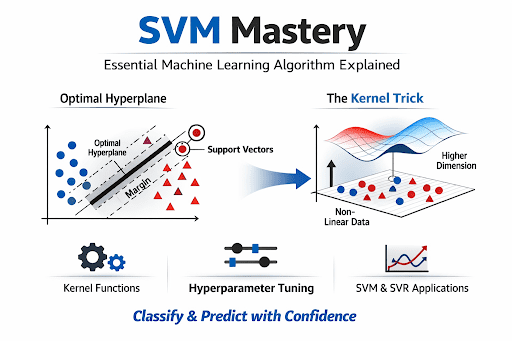
At its simplest level, a support vector machine works by finding a line or a hyperplane that separates different classes of data. In two dimensions, this is literally a line on a graph. In three dimensions, it becomes a flat plane. In higher dimensions, we call it a hyperplane, but the idea remains the same: a clear dividing line between categories.
What sets SVM apart is the criteria it uses to select this dividing line. The algorithm does not just pick any line that separates the data. It searches for the line that sits as far away as possible from the nearest points on either side. This distance between the line and the closest points is called the margin, and SVM is obsessed with making it as large as possible.
The Critical Few: Support Vectors
Here is where the name support vector machines comes from. The data points that sit closest to the dividing line are called support vectors. Think of them as the pillars that hold up the decision boundary. If you move any other data point that is far from the line, the boundary stays exactly the same. But if you move a support vector, the entire boundary shifts.
This property makes SVM incredibly efficient. Once the model is trained, it only needs to remember these support vectors. The rest of the training data can be discarded. This is why support vector machines are known for being memory efficient, especially when compared to algorithms that require storing entire datasets.
The Wisdom of Wide Margins
Why does maximizing the margin matter so much? Consider a simple analogy. Two students are preparing for an exam. One student memorizes every single practice question perfectly but struggles when the actual test presents slightly different problems. Another student understands the underlying concepts and can solve any variation confidently.
The first student has a narrow margin of success, memorizing specifics without understanding principles. The second student has a wide margin, possessing deep understanding that generalizes to new situations. Support vector machines aim for this wide margin philosophy. By maximizing the distance between classes, they build models that generalize beautifully to new data, avoiding the trap of overfitting.
The Magic of the Kernel Trick
Perhaps the most ingenious aspect of support vector machines is something called the kernel trick. This mathematical sleight of hand allows SVM to solve problems that would otherwise be impossible.
When Straight Lines Are Not Enough
Many real world problems cannot be solved with a straight line. Imagine trying to separate red dots arranged in a circular pattern from blue dots surrounding them. No single straight line can do this. You need a curved boundary. Traditional linear classifiers would fail here, but support vector machines have a solution.
The kernel trick transforms the data in a way that makes the problem solvable with a straight line in a higher dimensional space. Think of it like taking a flat piece of paper with a messy drawing and folding it into a three dimensional shape where the drawing suddenly becomes organized. The SVM performs this transformation mathematically without actually moving the data.
Common Kernel Functions
Different kernels serve different purposes, and choosing the right one is part of the art of building effective support vector machines.
The linear kernel is the simplest and most straightforward option. It works beautifully when your data is already well separated or when you have a very large number of features. Text classification problems often use linear kernels because the high dimensional word feature space naturally lends itself to linear separation.
The polynomial kernel introduces curves and interactions between features. It can capture relationships that linear kernels miss, but it requires careful tuning to avoid creating overly complex boundaries. The degree parameter controls how wiggly your decision boundary becomes.
The radial basis function kernel, often called the RBF kernel, is the most popular choice for complex problems. It creates localized decision boundaries, meaning each data point influences only its immediate neighborhood. The gamma parameter determines how far this influence reaches. Small gamma values create smooth, flowing boundaries while large gamma values create tight, intricate boundaries that may follow noise in your data.
Choosing Your Kernel Wisely
Selecting the right kernel for your support vector machine model is part science and part experience. For text data with thousands of features, the linear kernel is often your best starting point. For image recognition or complex biological data, the RBF kernel usually delivers superior results. The perceptron machine learning guide offers historical perspective on how early linear classifiers evolved into the sophisticated kernel methods we use today.
When in doubt, cross validation is your trusted guide. By testing different kernels and comparing their performance on held out validation data, you can empirically determine which option best captures the underlying patterns in your specific problem.
Beyond Classification: Support Vector Regression
While support vector machines are famous for classification, the same principles extend elegantly to predicting continuous values.
Rethinking Regression with SVM
Traditional regression tries to fit a line or curve that minimizes the distance between predictions and actual values. Support vector regression, or SVR, takes a different approach. Instead of penalizing every error, SVR defines a tube of tolerance around the predicted values. Errors inside this tube are ignored completely. Only predictions that fall outside the tube contribute to the loss function.
This approach makes SVR remarkably robust to noise and outliers. Small fluctuations in your data do not send the model into chaos. It focuses only on the errors that truly matter, those that exceed your tolerance threshold.
Practical Applications of SVR
SVR finds applications wherever precise predictions with acceptable error bands are valuable. Financial analysts use it to forecast market trends with defined confidence intervals. Energy companies employ it to predict power consumption, understanding that small deviations are acceptable while large errors require attention. Manufacturing facilities leverage SVR for quality control, setting tolerance limits that distinguish acceptable variation from defects.
Building Your SVM Model
Creating effective support vector machines models requires attention to detail and a systematic approach.
The Critical Importance of Scaling
Here is a mistake that trips up many beginners. Support vector machines rely entirely on distance calculations. If one feature ranges from 0 to 1 and another ranges from 0 to 10,000, the larger feature will completely dominate the distance calculations. Your model will essentially ignore the smaller feature, even if it contains valuable information.
Scaling solves this problem. Standardization, which transforms each feature to have zero mean and unit variance, ensures every feature contributes equally. The rise of modern machine learning has highlighted how proper preprocessing often matters more than algorithm selection for achieving good results.
Tuning Your Hyperparameters
Support vector machines come with several knobs to turn, and finding the right settings makes all the difference.
The regularization parameter, often called C, controls how strictly your model adheres to the training data. A small C value creates a wider margin with more tolerance for errors. This approach promotes generalization and helps avoid overfitting. A large C value pushes the model to classify every training point correctly, which can lead to memorizing noise rather than learning patterns.
For the RBF kernel, the gamma parameter determines the radius of influence for each training point. Low gamma values create smooth, global boundaries that capture broad patterns. High gamma values create localized, intricate boundaries that may follow the quirks of your training data.
Finding the Sweet Spot
The best hyperparameters for your support vector machines model depend entirely on your data. There is no universal setting that works for every problem. Cross validation techniques like grid search systematically explore combinations of parameters, evaluating each option on validation data to identify the configuration that delivers the best generalization performance.
Real World Success Stories
Support vector machines have powered remarkable achievements across industries, proving their value time and again.
Transforming Healthcare Diagnostics
Medical diagnostics demands accuracy. Mistakes carry serious consequences. Support vector machines have risen to this challenge, helping doctors detect cancer from medical images, classify diseases based on genetic markers, and predict patient outcomes from clinical data. The ability to deliver reliable predictions even with limited training samples makes SVM invaluable in medicine, where large datasets are often difficult to assemble.
Powering Financial Intelligence
Banks and financial institutions rely on support vector machines for critical decisions. Credit scoring models built with SVM help determine who receives loans. Fraud detection systems use SVM to flag suspicious transactions in real time. Algorithmic trading strategies incorporate SVM predictions to identify market opportunities. These modern artificial intelligence applications demonstrate how SVM contributes directly to business success.
Advancing Scientific Discovery
Researchers in bioinformatics use support vector machines to unlock mysteries of life. Protein classification helps understand cellular functions. Gene expression analysis aids in identifying disease markers. Drug discovery leverages SVM to predict how compounds interact with biological targets. The algorithm’s ability to find patterns in high dimensional biological data accelerates scientific progress.
Advantages Worth Celebrating
The enduring popularity of support vector machines stems from genuine strengths that other algorithms struggle to match.
Grace Under Pressure
When faced with high dimensional data, many algorithms falter. Support vector machines thrive. Whether you are analyzing text documents with tens of thousands of unique words or processing genetic data with countless gene expressions, SVM handles the complexity with confidence.
Memory That Matters
After training, support vector machines only remember the support vectors, the critical few points that define the decision boundary. This efficiency means your models use less memory and make predictions faster than algorithms that require storing entire training datasets.
Built to Generalize
The margin maximization principle gives SVM a built-in defense against overfitting. By focusing on creating the widest possible separation between classes, the algorithm naturally builds models that perform well on new, unseen data.
Limitations to Consider
Honest assessment requires acknowledging where support vector machines face challenges.
Training Time Tradeoffs
When your dataset grows to millions of examples, training support vector machines can become painfully slow. The optimization problems at the heart of SVM scale poorly with sample size. The rise of neural networks AI evolution has addressed scalability challenges that SVM encounters with massive datasets.
The Black Box Problem
While more interpretable than deep neural networks, support vector machines are less transparent than decision trees. Understanding why a particular prediction was made requires additional analysis. For applications where explainability matters, this limitation deserves consideration.
Parameter Sensitivity
The performance of support vector machines depends heavily on choosing appropriate kernels and hyperparameters. Finding the right settings requires experimentation and validation, which can be time consuming.
Frequently Asked Questions
1. Can support vector machines handle more than two classes?
Absolutely. While SVM is naturally a binary classifier, it handles multiclass problems through strategies like one versus one or one versus all. Multiple SVM models are trained, and their predictions are combined to determine the final class.
2. What happens if I forget to scale my features?
Your model will become biased toward features with larger numerical ranges. A feature ranging from 0 to 10,000 will dominate distance calculations, and features with smaller scales will be effectively ignored regardless of their importance.
3. When should I use the RBF kernel over the linear kernel?
Start with the linear kernel when you have high dimensional data or suspect linear separability. If results disappoint, switch to the RBF kernel for its flexibility in handling complex, non linear relationships. Cross validation will confirm the better choice.
4. How do I know if my SVM model is overfitting?
Watch for a large gap between training accuracy and validation accuracy. High training accuracy coupled with poor validation performance signals overfitting. Adjusting the C parameter or gamma value typically helps.
5. Is SVM still relevant with the rise of deep learning?
Yes, absolutely. For structured data, smaller datasets, and problems requiring interpretability, SVM remains competitive with and sometimes superior to deep learning approaches. Many practitioners maintain SVM in their toolkit alongside neural networks.
Conclusion
Support vector machines represent one of machine learning’s most elegant achievements. They combine intuitive geometric principles with sophisticated mathematical foundations to deliver models that are both powerful and reliable. From their obsession with maximizing margins to the ingenious kernel trick that unlocks complex patterns, SVM offers a complete framework for solving real world problems.
While newer algorithms have captured headlines, support vector machines continue earning their place in production systems across healthcare, finance, manufacturing, and beyond. Their efficiency with high dimensional data, memory friendly design, and built in resistance to overfitting make them invaluable tools for practitioners who value both performance and reliability.
For data scientists seeking to build models that stand the test of time, mastering support vector machines remains an essential skill. The algorithm’s blend of theoretical beauty and practical utility ensures its relevance for years to come.